Predict-then-Diffuse accepted at IJCNN
I am very happy to share that our paper Predict-then-Diffuse: Adaptive Response Length for Compute-Budgeted Inference in Diffusion LLMs has been accepted at IJCNN 🎉
Read the paper on arXiv: https://arxiv.org/html/2605.04215v1
This post is a practical walkthrough of the core idea, why we worked on it, and why it matters even if you are not deeply into Large Language Models research.
Table of contents
- Why does this problem exist? 🤔
- The core idea in one sentence 💡
- How does Predict-then-Diffuse work? ⚙️
- Why is this useful beyond research? 🚀
- A bit of technical detail (without overkill) 🧠
- What did we observe in experiments? 🔬
- For non-technical readers: why should you care? 🌍
- What does this not solve? ⚠️
- Why was this fun to work on? ❤️
Why does this problem exist? 🤔
Most people today are familiar with chat models that generate text one token at a time. Diffusion LLMs are different: they generate tokens in parallel. This sounds like a pure win, and in many ways it is.
But there is a catch.
Before generation starts, a diffusion LLM must decide how long the answer canvas is. If the model expects a short answer but the user needs a long one, the answer is cut. If it expects a long answer and the real answer is short, it wastes computation on empty space.
That empty space is not free.
In these models, a lot of the compute grows with the square of the sequence length. So over-allocating length by a lot can become expensive very quickly.
A non-technical analogy 📦
Imagine printing shipping labels.
- If every package always gets the largest label size, you waste paper for small packages.
- If you always start with tiny labels, many large packages must be relabeled and processed again.
Either way, the system is inefficient.
Our paper does the obvious thing that usually gets skipped in deployment: estimate label size before printing. In our case, estimate response length before generation.
The core idea in one sentence 💡
Given an input prompt, we first predict how long the answer is likely to be, then run diffusion generation with that length instead of using a fixed global maximum.
That is why we call it Predict-then-Diffuse.
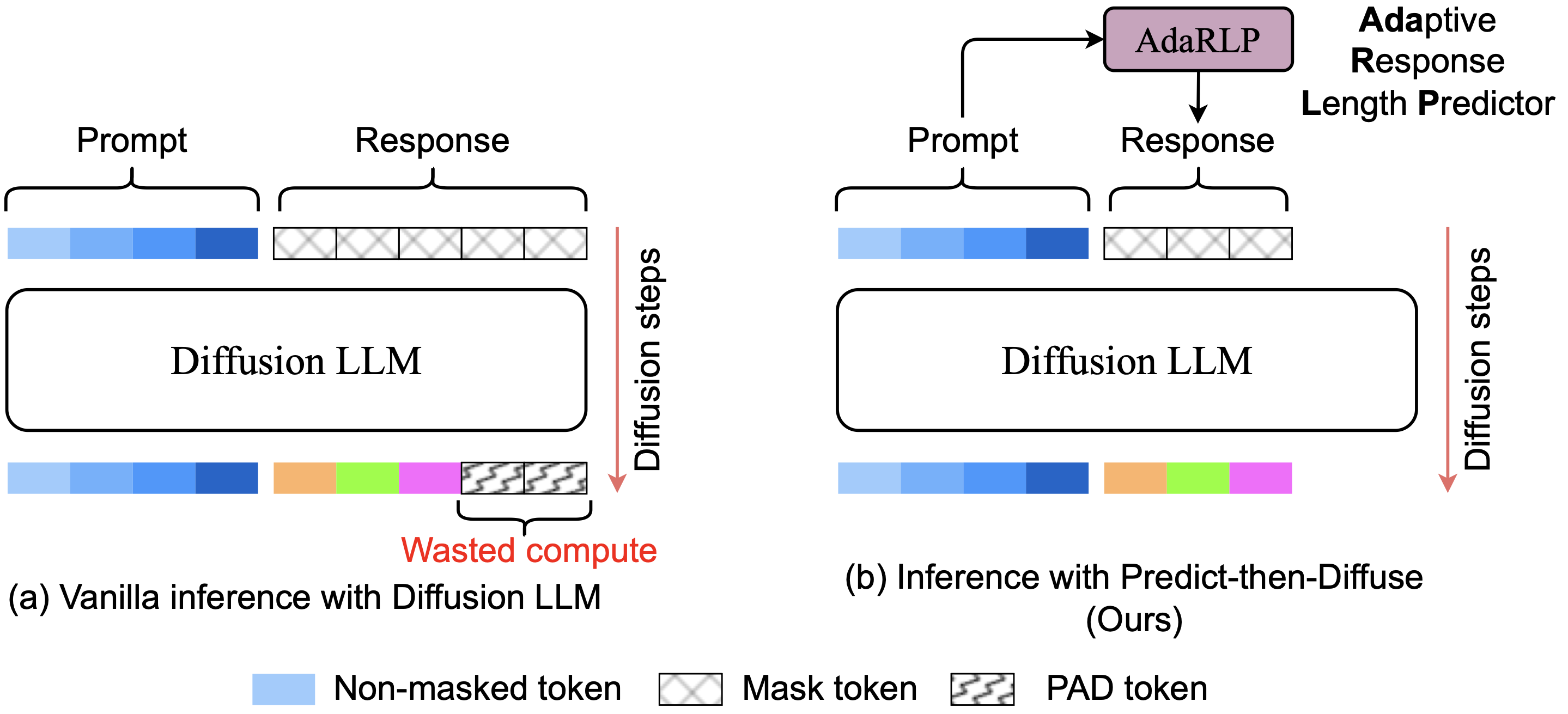
How does Predict-then-Diffuse work? ⚙️
What did we actually build?
The framework has three pieces:
- Length Predictor (AdaRLP): a lightweight model that takes the prompt and predicts output length.
- Safety Margin: a small data-driven extra buffer added to avoid underestimation.
- Fallback: only in rare failure cases, rerun with a larger length.
The design goal was simple: save compute without hurting output quality.
Why is this useful beyond research? 🚀
There are at least three practical benefits.
1) Lower cost 💸
If most answers are short but your system always allocates very long canvases, your infrastructure burns compute on padding. Adaptive sizing reduces this waste.
2) Better latency stability ⏱️
Naive heuristics (for example, repeatedly doubling length after failure) can create random latency spikes. A predictor with a safety margin makes one-shot generation much more frequent.
3) Cleaner operational planning 📊
When serving many requests, predictable compute is as important as average speed. This is especially true for production systems that must meet strict response-time and reliability targets.
A bit of technical detail (without overkill) 🧠
Before this part, two quick definitions:
- Inference means generating an answer after a user sends a prompt.
- A transformer is the neural network architecture used by most modern language models.
In transformer models, one important part of the computation scales as
Our approach is model-agnostic, which means it does not depend on one specific diffusion model design. You can place the length predictor before generation without retraining the main diffusion model.
In our experiments, we used a lightweight CatBoost model (a fast machine-learning method) to predict response length. Its runtime overhead is tiny compared to the generation step.
What did we observe in experiments? 🔬
On our benchmark setup, Predict-then-Diffuse reduced total compute substantially relative to fixed-length inference, while keeping fallback events rare.
The exact percentages depend on the response-length distribution of the workload, but the trend was very clear:
- fixed max length is robust but very wasteful,
- static heuristics can look good on specific datasets but are brittle,
- prompt-conditioned prediction is more robust across variable workloads.
An important takeaway is that data distribution matters a lot. If your workload is skewed to short outputs, many methods look good. If it is mixed or bimodal, naive heuristics can break down quickly.
For non-technical readers: why should you care? 🌍
Because this is one of those improvements that can make AI systems:
- cheaper to run,
- more predictable for users,
- less wasteful in energy and hardware usage.
People often focus only on model quality. In real deployments, system behavior under load matters just as much.
What does this not solve? ⚠️
It does not magically make every diffusion model better at reasoning.
It does not remove all worst-case latency scenarios.
It does not replace good serving infrastructure.
What it does is provide a practical and low-overhead mechanism to avoid wasting large amounts of compute due to fixed response length.
Why was this fun to work on? ❤️
I like this type of work because it sits at the intersection of ML and systems:
- the ML part predicts the required resource,
- the systems part uses that prediction to improve runtime behavior,
- the final metric is not just accuracy but operational efficiency.
To me, this is where many useful AI contributions will keep happening: not only in bigger models, but in better ways to run them.
Paper: Predict-then-Diffuse: Adaptive Response Length for Compute-Budgeted Inference in Diffusion LLMs (IJCNN 2026).