Beware of the mean
The central limit theorem, together with the law of large numbers, is one of the most fascinating theorems of statistics. Their applications range from economics to biology and therefore are popular and well known among scientists. However, I found that it’s very common to forget the hypotheses behind them and apply them even when they do not work. Or better, to apply them where they may work on paper but not in the real world. This is mainly due to oversimplification when recalling these theorems. For instance, regarding the central limit theorem, many people just remember that averages tend to become Gaussian under suitable conditions. Well, this is, of course, true, but the rate at which the distribution of the averages converges to the true mean changes a lot depending on the initial distribution type.
Table of contents
The Central Limit Theorem
First of all, let’s review the formal definition of the Central Limit Theorem (from now on called CLT). It is important to note that there are different variants of the CLT but we’ll refer to the Lindeberg–Lévy’s one.
Theorem
Given a sequence of i.i.d. random variables
Explanation
The classical central limit theorem describes the size and the distributional form of the stochastic fluctuations around the deterministic number
More precisely, it states that as
gets larger, the distribution of the difference between the sample average and its limit , when multiplied by the factor , that is, , approaches the normal distribution with mean and variance . For large enough , the distribution of gets arbitrarily close to the normal distribution with mean and variance .
The usefulness of the theorem is that the distribution of
What does this mean to us?
Translating the mathematical formulas into jargon, less clean, but more clear while at the same time comprehensive, it says this:
The distribution of the means of
Extra: Other variants of the CLT require additional conditions like Lyapunov’s one that asks for independence between the random variables but not that they are identically distributed. If a sequence of random variables satisfies Lyapunov’s condition, then it also satisfies Lindeberg’s condition. The converse implication, however, does not hold.
Where is the problem?
Plainly speaking, CLT is used in a lot of contexts to handle a distribution that differs from a normal like a normal. Because, as some remind it: “All distributions end up being Gaussian”. This is useful but it can be misused very easily. Indeed while on paper it works in reality it doesn’t, and this is why.
While for many distribution shapes a rule of thumb is that CLT effects become visible around
Now we’ll demonstrate it through numerical tests.
Let’s start using a uniform distribution between 0 and 1
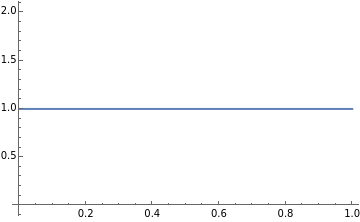
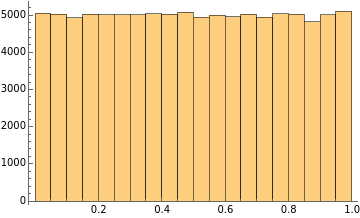
At this point, let’s sample
Here things start to get interesting. If we sample 2 elements and sum them up
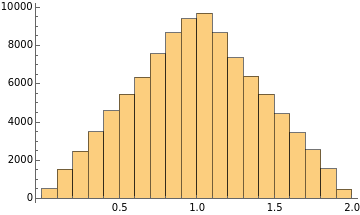
As you can see, the distribution is already not flat. The most likely probability is at 1 because to get 1 there are a lot of combinations, while to get 0 or 2 you need a lot of work because only 0 can give you 0, and only 2 can give you 2.
CLT is already working, if you sum numbers or average numbers you end up with a Gaussian. The problem is that this example reaches the central limit very quickly. But this is not always the case.
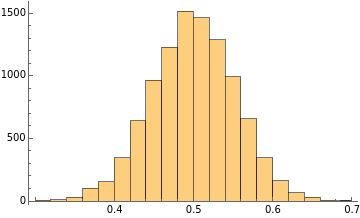
For those who don’t believe until they see, here it’s the distribution of the averages. We start creating
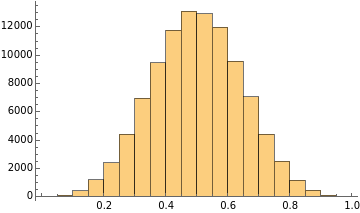
I want to make a little digression here to fully understand how the central limit theorem works in practice. From now on, we’ll work on the averages of the sample sets. Specifically, this digression will focus on how the final distribution changes its shape depending on the dimension of each sample set. We note an interesting behavior that can be summarised as follows:
As the dimension of each sample set increases, the final distribution has lower variance around the mean.
This is due to the law of large numbers, in fact, as the dimension of each sample set grows, the mean of the sample set will tend to the true mean better and better.
Sample size: 30
Number of sample sets:
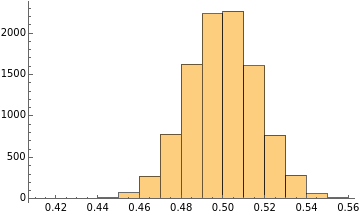
Sample size: 300
Number of sample sets:
Until now, everything worked as expected… Let’s try to break it. We’ll use a Pareto distribution. The Pareto distribution is a power-law distribution. For those interested in the technical details, here is the formal definition:
And this is the distribution shape:
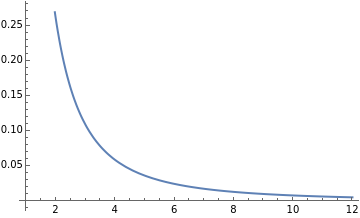
In this example, we’ll use a Pareto distribution with shape parameter (
Now let’s do the same we have done before but this time using the Pareto distribution.
This is the result with a sample size of 30 and
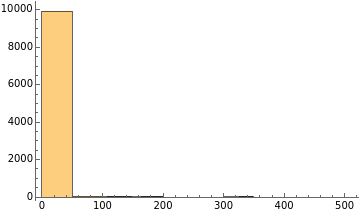
This result might seem unexpected, but it’s not an error. As everybody can see, the distribution significantly deviates from a Gaussian shape. No matter how you look at it.
If you understand why this happens then you may say: “Let’s increase the number of sample sets”.
In fact, the theorem states “when
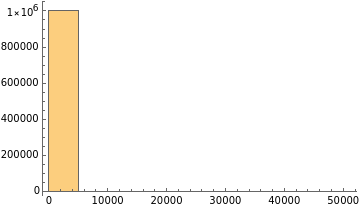
Still no bell shape on the horizon. We could continue increasing the number of sample sets, but we stop here because to get a bell shape, with a sample size of 30, you need
However, no matter how you see this, it has a lot of implications. If you are using CLT in the real world on a fat-tailed distribution you will be dead way before your model starts to work.
To help you grasp how big is
What can we bring home from this?
Well, there are two different reasons this happens:
- First of all, the Pareto distribution with
has infinite variance and CLT requires bounded variance.
But while this is true, the Pareto distribution actually obeys the condition of bounded mean of the Law of Large Numbers.
- This means that (and this is also due to the infinite variance) despite it being bounded, the mean jumps around a lot.
This means that to compress the variance and to get the mean with the same reliability as a non-fat-tailed distribution you need a lot more work.
All this work brings us to the conclusion that when working with fat-tailed distributions, applying the CLT to know the mean may not be a good idea (here I’m ironically optimistic). Actually, looking for the mean may not be a good idea at all because, for a fat-tailed distribution, it is not a very robust property.